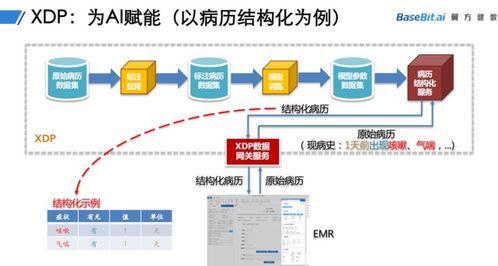
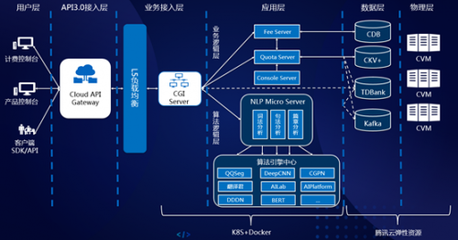
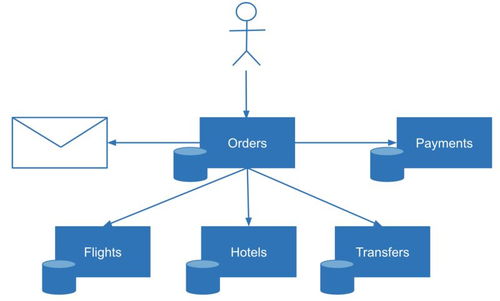
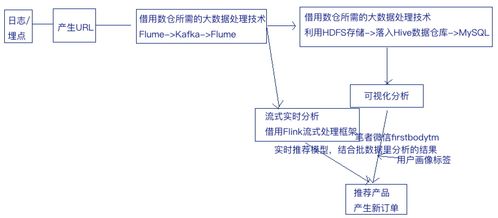
在數據成為核心生產要素的數字時代,企業面臨著數據量爆炸式增長、數據類型多樣化、訪問協議復雜化以及實時處理需求迫切的嚴峻挑戰。傳統存儲架構往往因協議割裂、擴展性差、管理復雜而難以適應。Umtor作為一款先進的分布式多協議統一存儲系統,結合其強大的數據處理服務,正為企業構建下一代數據基礎設施提供卓越的實踐方案。
一、 分布式多協議統一存儲:打破數據孤島
Umtor的核心優勢在于其“統一”的設計哲學。它在一個統一的存儲資源池上,原生支持包括NFS、SMB/CIFS、S3、HDFS、iSCSI等多種存儲訪問協議。這意味著:
- 協議融合:無論是來自虛擬化平臺、大數據分析集群、AI訓練框架,還是傳統的文件服務器應用,其數據都可以存入同一個存儲池中,徹底消除了因協議不同而導致的數據孤島。
- 數據互通:同一份數據可以通過不同的協議被訪問和使用,例如,通過S3接口寫入的對象數據,可以同時通過NFS協議被前端應用以文件形式讀取,極大提升了數據的流動性和利用率。
- 簡化管理:管理員無需為不同協議維護各自獨立的存儲系統,通過一個控制平面即可管理所有存儲資源、權限和策略,運維復雜度顯著降低。
其分布式架構確保了系統的彈性與可擴展性。采用無中心節點的對等架構,容量和性能均可通過橫向增加節點實現線性擴展,能夠從容應對從TB到EB級的數據增長,并提供高并發、低延遲的訪問體驗。數據通過多副本或糾刪碼機制在集群內分布式存儲,保障了極高的可靠性與可用性。
二、 數據處理服務:讓存儲“智能化”
Umtor不僅僅是一個被動的數據存儲倉庫,更通過集成內置的數據處理服務,賦予了存儲系統主動處理數據的能力,實現了“存算融合”的進階實踐。
- 近數據計算:在數據存儲的本地或近端,Umtor可以提供計算框架(如容器化環境),允許用戶將數據處理任務(如數據清洗、格式轉換、特征提取、AI模型推理)直接下發到存儲集群執行。這避免了數據在存儲和計算集群間的大量遷移,極大降低了網絡帶寬消耗,并提升了處理效率。
- 實時數據處理:支持與流處理引擎(如Flink、Spark Streaming)深度集成,能夠對持續寫入的數據流進行實時分析與響應,為風控、監控、推薦等場景提供即時洞察。
- 數據生命周期與自動化策略:結合數據處理能力,Umtor可以實現智能化的數據生命周期管理。例如,系統可自動將熱數據存儲在高速存儲層,并對冷數據進行分析、壓縮、歸檔至低成本存儲層;或根據預設策略,自動觸發數據備份、復制、轉碼等處理任務。
三、 一體化實踐帶來的核心價值
將分布式多協議統一存儲與數據處理服務相結合,Umtor的實踐為企業帶來了多維度的價值提升:
- 降本增效:硬件資源利用率最大化,管理運維成本大幅降低,數據處理效率因“就近計算”而顯著提升。
- 敏捷創新:統一的數據底座和靈活的數據處理能力,使得業務部門能夠快速獲取所需數據并試驗新想法,加速數據分析、AI應用等創新業務的落地。
- 數據價值深化:打破了數據訪問與利用的壁壘,使得全量數據的融合分析成為可能,從而挖掘出更深層次的業務洞察與價值。
- 面向未來架構:這種架構天然契合云原生、混合多云、邊緣計算等現代IT趨勢,為企業構建可持續演進的數據平臺奠定了堅實基礎。
###
Umtor在分布式多協議統一存儲與數據處理服務方面的實踐,標志著企業存儲正從單一的“數據容器”向智能的“數據引擎”演進。它不僅是解決當前海量、多源、實時數據挑戰的技術方案,更是企業構建數據驅動核心競爭力、擁抱全面數字化未來的關鍵基礎設施。隨著技術的不斷迭代,此類一體化平臺必將成為數字時代企業數據管理的標準范式。